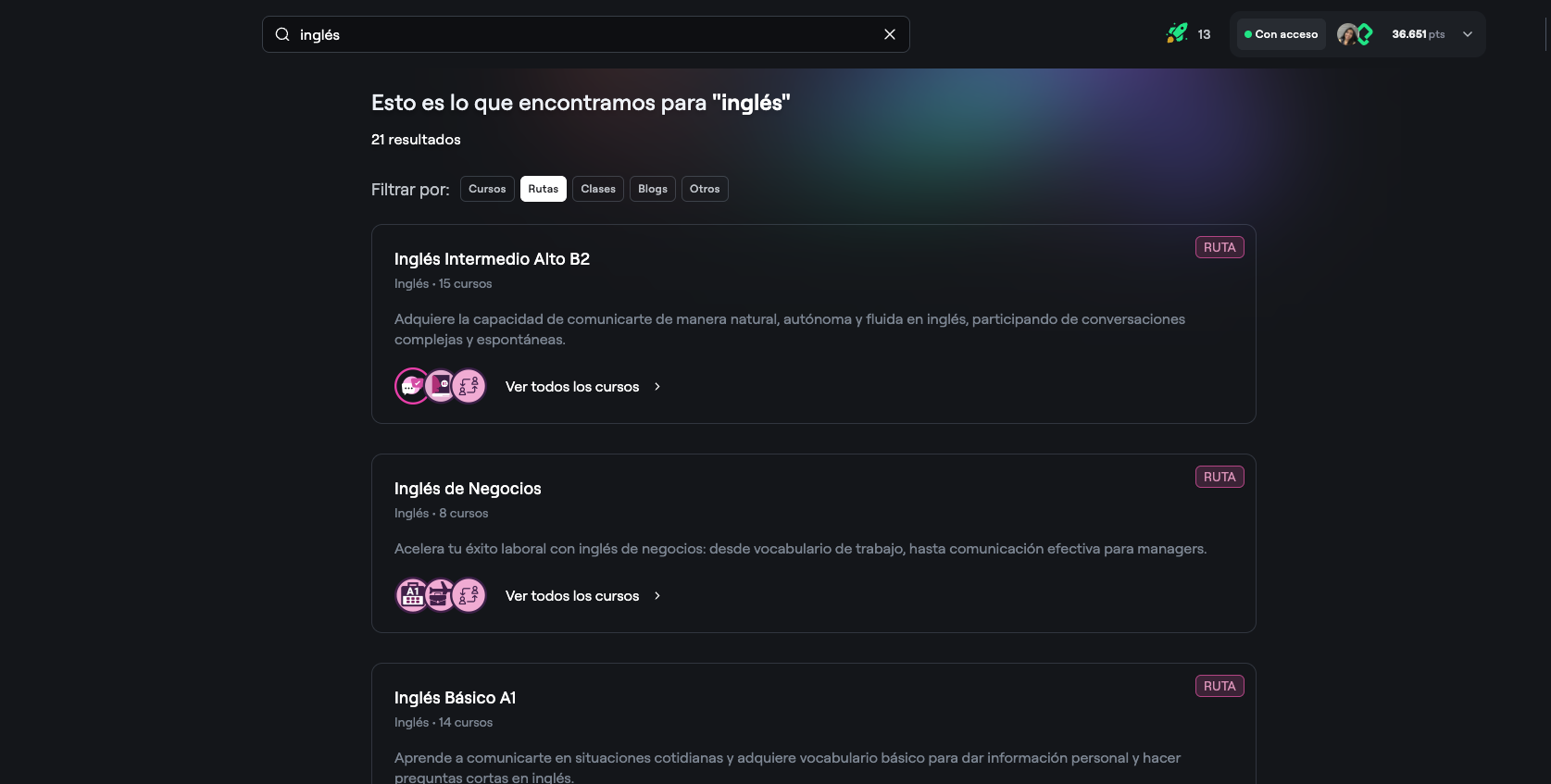
Search System Architecture
Content Vectorization
All platform content is converted into vector representations stored in a specialized database. For courses, we create separate vectors for titles and full content—this dual approach improves relevance by giving more weight to exact title matches while still capturing semantic meaning from descriptions and modules.
This vectorization happens automatically whenever new content is published, keeping the search index current without manual updates.
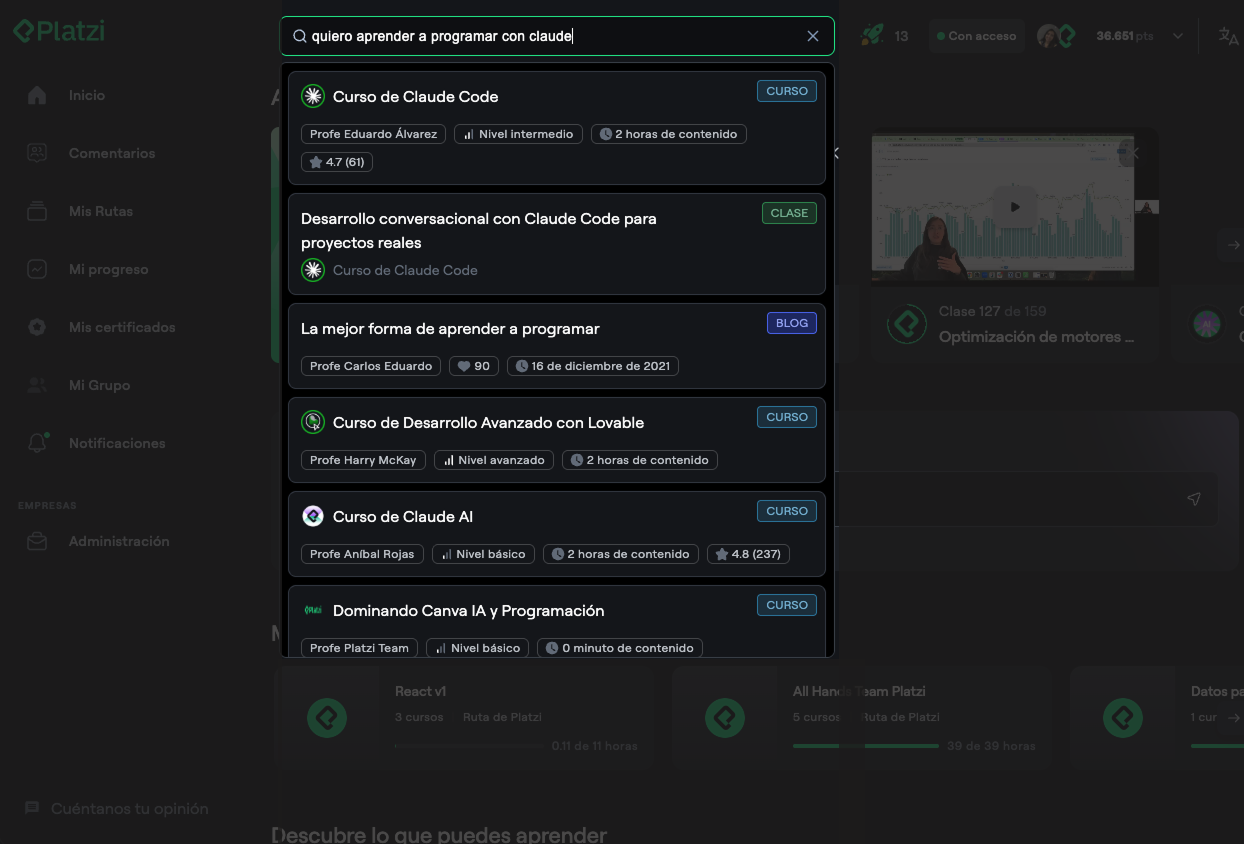
Personalized Query Processing
When a student searches, we combine their query with context about courses they've viewed in the past months. The vector database returns results above a minimum relevance threshold, ensuring only meaningful matches appear.
This personalization helps surface content aligned with their current learning trajectory while still allowing discovery of new topics.
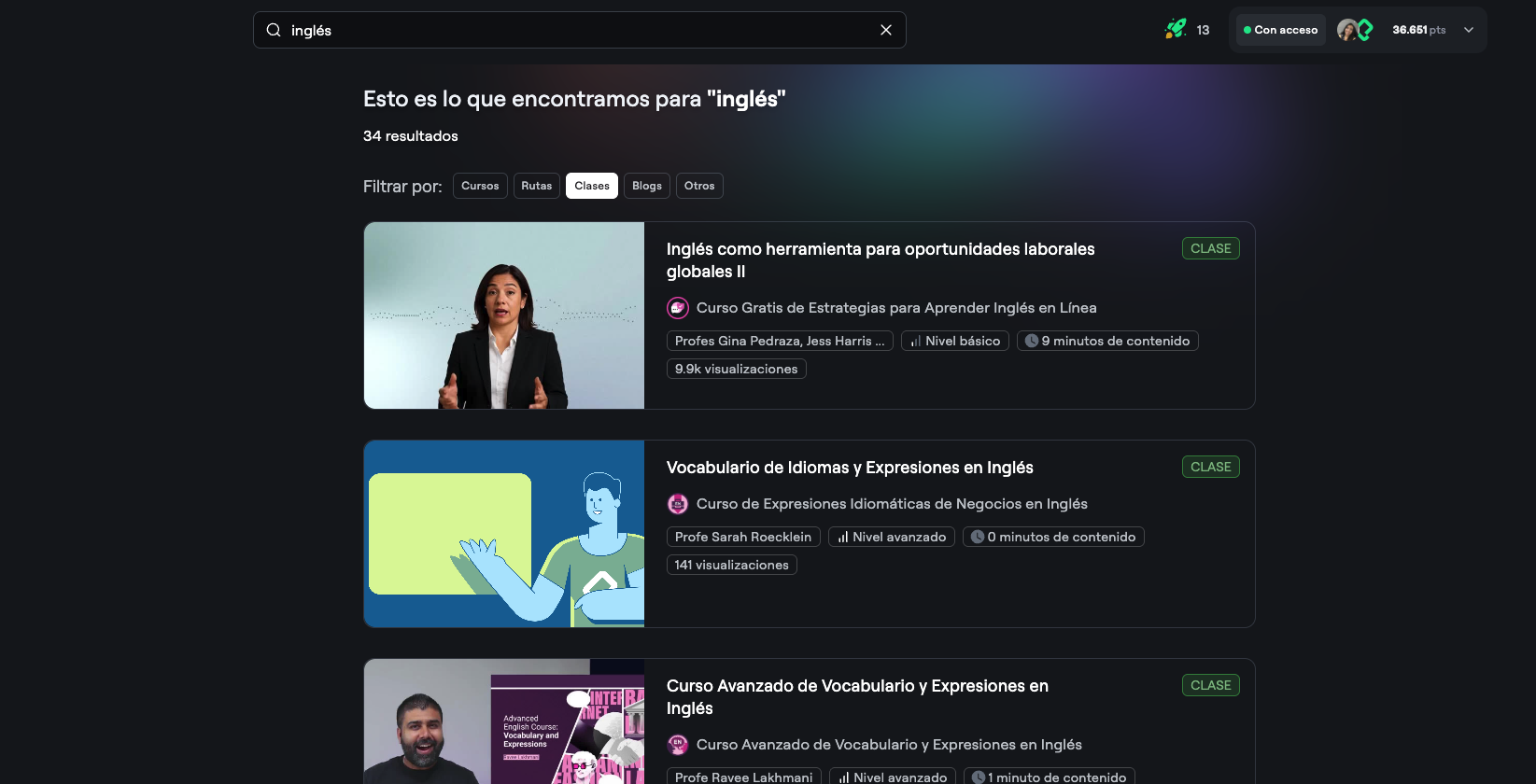
Intelligent Re-Ranking
Raw vector search results are re-ranked using multiple quality signals. Courses get bonus points if they relate to recently viewed content, have recent launch dates, or have higher student ratings and completion rates.
This mathematical reweighting ensures the final results balance relevance with quality, showing students the best matches first.
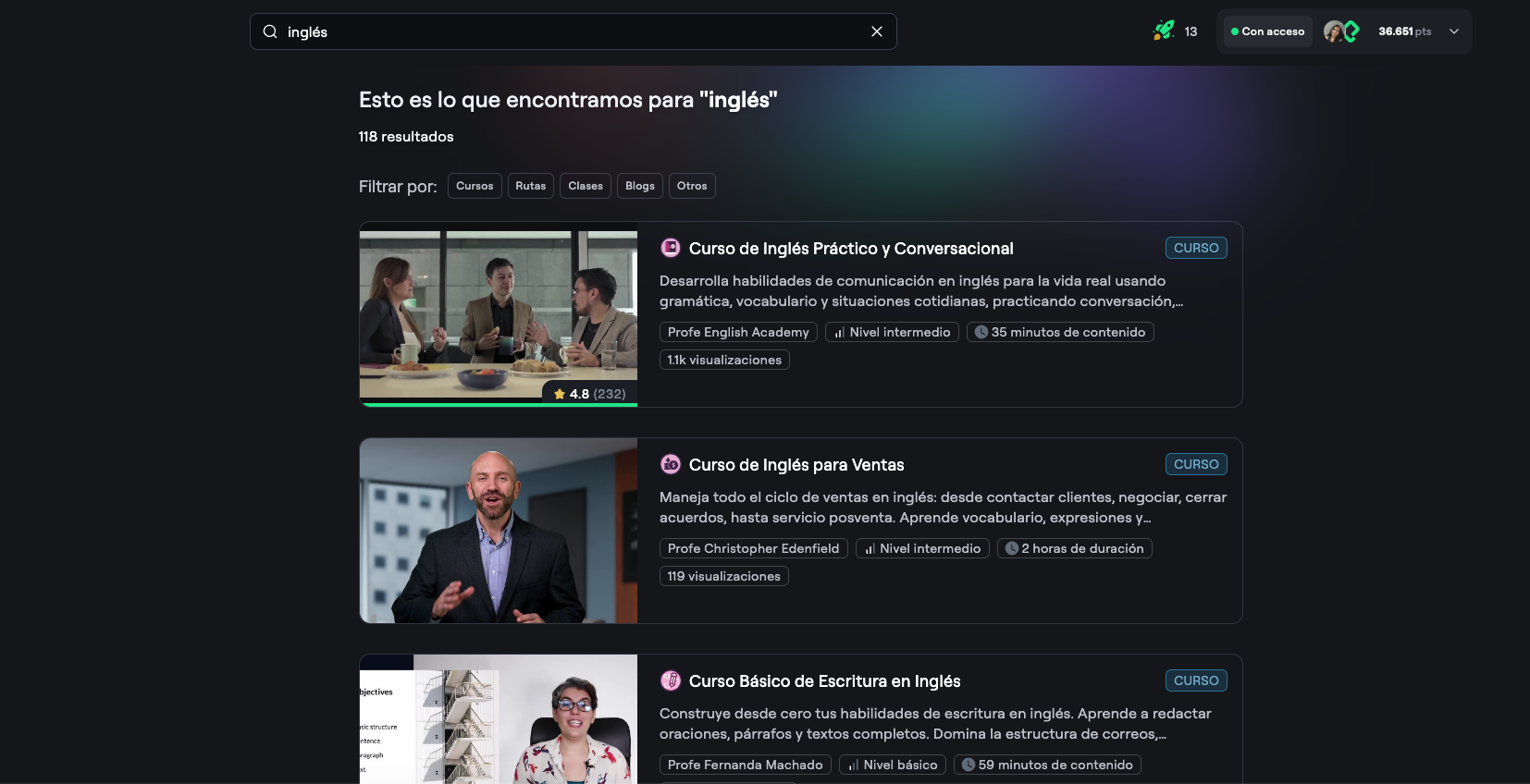
Unified, Scannable Results
The redesigned interface displays all content types in a clean, easy-to-scan layout optimized for quick decision-making. Students see more results above the fold, with clear visual differentiation between courses, paths, and other content.
This simplified design reduced cognitive load and made it easier for students to find and act on relevant content.